«В издательском бизнесе растут запросы»
Созданием лаборатории "больших данных" (от англ. big data) озаботились в российском издательском бизнесе. Предполагается, что она позволит перейти от "плоских" отчетов к прогнозной аналитике, которая снизит финансовые риски, изучив конкретного потребителя и рынок в целом, и увеличит прибыль. Кадры для таких целей компаниям придется "выращивать" самостоятельно, а так как работа подобных лабораторий связана с персональными данными, система должна быть еще и юридически компетентной, считают эксперты.
О создании собственной лаборатории "больших данных" объявили в "Эксмо-АСТ". Наем специалистов, настройка инфраструктуры, наполнение баз данных и апробация будут проходить в течение всего 2018 года. Ввиду сложности используемых подходов на получение первых бизнес-результатов может уйти еще не менее 9-12 месяцев с момента запуска лаборатории, говорится в концепции проекта.
Смысл лаборатории в том, чтобы научиться предугадывать практически все. Наибольший экономический эффект принесет прогнозирование производства и сбыта продукции. На второе место издатель ставит лучшее понимание предпочтений читателя, изучив которого, можно создать эффективные рекомендательные сервисы, влиять на продажи в Интернете, повышать лояльность потребителей. На третьем месте - повышение эффективности поддерживающих функций, например, анализ рисков по договорным документам.
Такие компании, как Nasdaq, Facebook, Google, IBM, Visa, MasterCard, Bank of America, HSBC, AT&T, Coca Cola, Starbucks и Netflix, были у истоков применения "больших данных" и сейчас тоже активно работают в этом направлении. Как правило, потребность в обработке таких данных возникает у компаний, которые сталкиваются со значительным и регулярным потоком информации. Чем он больше и интенсивнее, тем выше потребность в специфических технологиях обработки информации.
Большинство людей пользуются онлайн-сервисами, которые генерируют огромное число запросов. Формируется большой объем неструктурированных данных, которые необходимо обрабатывать, поэтому компании задумываются о создании лабораторий для анализа, поясняет руководитель проектного департамента Bell Integrator Михаил Лапин. При этом big data - это не какой-то определенный массив данных, а совокупность методов их обработки. Работа с данными не похожа на обычный процесс бизнес-аналитики. В этом случае результат получается в процессе их очистки путем последовательного моделирования: сначала выдвигается гипотеза, строится статистическая, визуальная или семантическая модель, на ее основании проверяется верность выдвинутой гипотезы и затем выдвигается следующая.
Данные о пользовательских действиях собирают с онлайн-ресурсов, далее их обрабатывают с использованием отдельного программного обеспечения, методов анализа данных и искусственного интеллекта, после чего формируют статистические отчеты, которые предоставляют подробную информацию о том, чем пользователи интересуются, что ищут, покупают. Процесс анализа идет в режиме реального времени, тем самым позволяя бизнесу более гибко подходить к стратегии развития и увидеть продукты и услуги, которые пользуются популярностью, а какие - нет, объясняет Лапин.
Спрос на технологии обработки "больших данных" есть и в традиционных отраслях. Его подстегивает расширение использования датчиков и устройств, которые позволяют собирать информацию с большей скоростью и в большем объеме. Например, страховые компании в Европе и США сейчас изучают возможность установки сенсорных устройств на автомобили клиентов. Это позволит сделать более гибкой ценовую политику, рассказывает ведущий специалист отдела аналитических исследований Института комплексных стратегических исследований Дмитрий Плеханов.
В России "большие данные" могут быть востребованы в финансовом секторе, интернет-коммерции, сотовых компаниях, возможны проекты на пересечении нескольких отраслей (есть примеры сотрудничества финансового сектора с соцсетями). На уровне городского хозяйства можно использовать "большие данные" для принятия решений о развитии транспорта, коммунальных сетей, охраны общественного порядка. Здесь интересен опыт Сан-Франциско, который размещает в открытом доступе большие объемы сведений о самых различных процессах, происходящих в городе, рассказывает Плеханов. Идея в том, чтобы сторонние разработчики могли использовать это на благо жителей (разрабатывать приложения и проводить исследования).
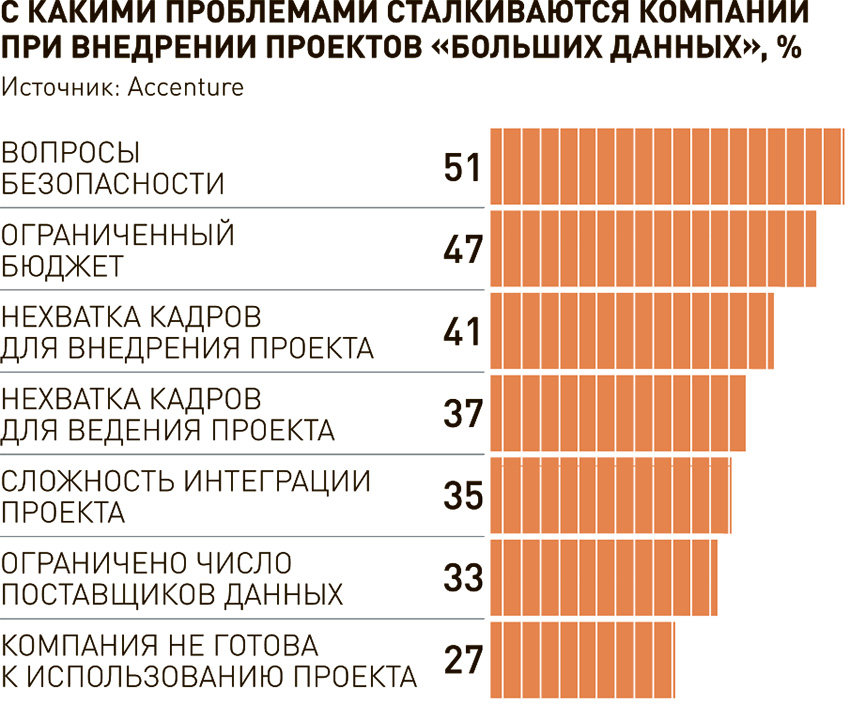
Спрос на информацию требует интеграции данных из разных источников и создания детальных баз о потребителях, ввиду чего все более актуальными становятся вопросы обеспечения безопасности персональных данных и недопущения их использования для дискриминации потребителей. С мая этого года в Евросоюзе вступит в силу закон, контролирующий эти процессы, говорит Плеханов. Основные претензии госрегуляторов к компаниям, собирающим досье на потребителей, связаны с тем, что компании, как правило, не информируют о том, каким образом будут использовать персональную информацию. Можно предположить, что со временем давление на участников рынка из-за этого будет только увеличиваться.